

The LLM Dilemma
The LLM Dilemma
As chatbots and so-called AIs are increasingly utilised, should we endavour to provide them with better information?

This is mainly in reaction to this article on The Guardian from Saturday March 16, 2024: “As AI tools get smarter, they’re growing more covertly racist, experts find.” There are many examples of this (some of them linked later in this essay), and my first question is, almost always, what is the cause of this?
As with many, many things in computer programming, the adage ‘garbage in = garbage out’ applies. On the one hand, companies like Google, Open AI and Microsoft are not forthcoming about what the actual training data for their AIs were (and are). If Dennis Layton is correct, ChatGPT-3 was trained on:
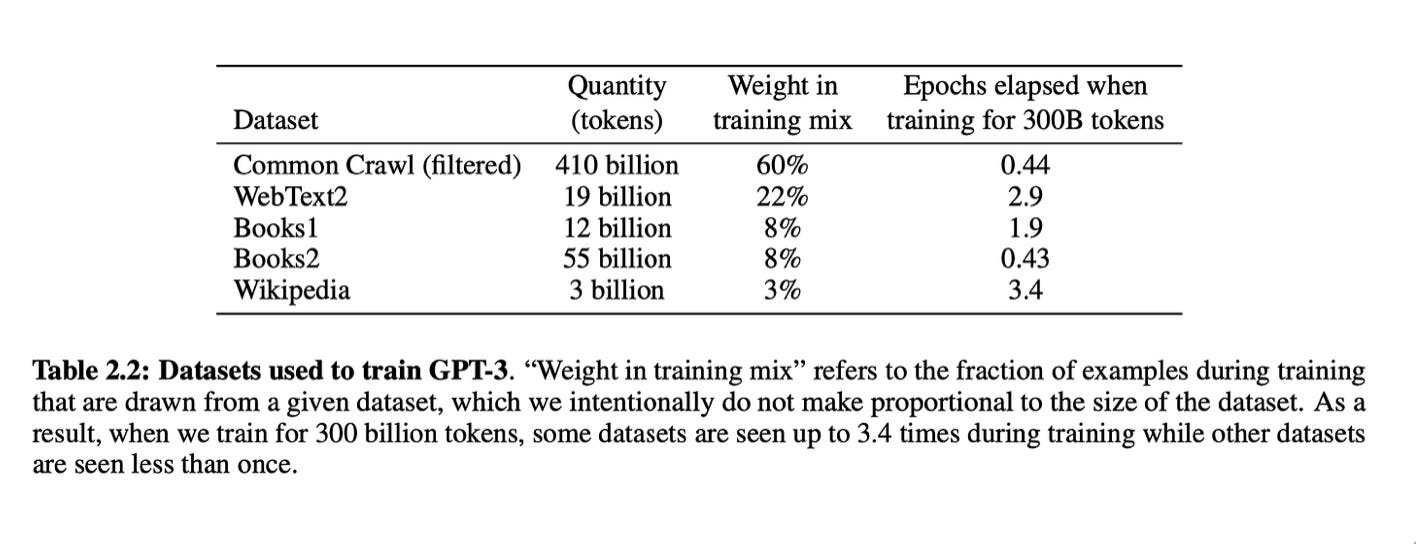
Thus, the great majority—about 82%—of ChatGPT’s training data was from the web. The Common Crawl used was a dataset containing data collected from the web between 2016 to 2019. Webtext2 is the text of all outbound Reddit links from posts with 3+ upvotes.
Has this data been curated? I strongly suspect not, if only due to the huge1 amount2. Therefore, there is no way that this data crawled from the internet is without bias. Here’s my hypothesis3: the majority of that data4 leans towards the PoV of white conservative males.

The consequences of this have showed up time and again. AI image generators often give racist and sexist results, hallucinating historically inaccurate images. Since these examples have been widely publicised, the programmers-annex-curators of OpenAI and Google have been scrambling to suppress these racist results. As a consequence—if they don’t fix the rooot cause, namely the highly biased training data—ChatGPT and Google’s Gemini have learned to become more covertly racist, as per the above-mentioned article in The Guardian. That article also demonstrates the increased utilisation of AI: they’re being used to determine which people to hire5. As The Who had it: “Welcome to the new boss, same as the old boss.”

Combine the above with the fact that nobody truly knows how huge LLMs really work. Again, as per the above-mentioned artice by Dennis Layton, ChatGPT-3 uses 175 billion parameters. How can any human—or group of humans—keep track of that?
Thus, the problem: if the AIs have so-called ‘algorithmic biases’, then how are we going to fix these when we don’t know how the algorithm works? I’m not the first to notice this, for example check Jeff Raikes’ article on Forbes: “AI can be racist, let’s make sure it works for everyone.” or Datatron’s “Real-life Examples of Discriminating Artificial Inteligence”. Part of the solution (as mentioned in the first article): “create full-spectrum training sets that reflect a richer portion of humanity.” Which will not be easy, and so far, while efforts like the Algorithmic Justice League are working towards this, I don’t see any signs of the major players (Google, OpenAI and Microsoft) implementing these highly necessary changes6.

The second problem—as mentioned above—is that the LLM powering these AIs are basically black boxes. Nobody knows how they really work. So if we don’t know how they work, how are we going to fix them?
The current major players seem content to relentlessly keep developing larger versions of their current AIs while taking no action to address the bias problem. So the only way we—let’s call us the ‘richer part of humanity’—can influence these AIs seems to be by feeding them more training data; that is, give them (more) access to our personal data. But do ‘we’ really want to do that?
If many others are like me; that is, extremely reluctant to let Big Tech know everything about oneself, even more reluctant to allow their works to be scraped7, then that option seems highly undesirable. Meaning that AIs and chatbot will remain biased (read: racist and misogynistic, albeit more covertly).
So here’s the LLM Dilemma: should we open ourselves up to it—and thus to Big Tech—in order to make them less biased (read: racist or misogynistic) and lose our privacy along the way, or stay mum and let the AIs retain their biases?
Personally, I would greatly prefer if either the major AI players would take proactive approaches to unbias the training data for their AIs (which doesn’t seem to be happening), or otherwise for legislation enforcing that (ibid). Therefore, short of opening our private data completely to Big Tech, the other thing we can do is support the Algorithmic Justice League (I donated) or people like Cynthia Rudin or Alexei Efros in their efforts to shine light into AI’s black boxes, and hope that the legislative-powers-that-be implement strict regulations8 (of which the European Union’s AI Act, endorsed by the European Parliament on March 13 is the first9).
In the meantime—if you didn’t already—take all results from AI with a large pinch of salt, and try to avoid using or being used by AI. The latter, as more firms are following the AI hype an implement its use, will become increasingly difficult.
Author’s note: what both baffles and frightens me more is that the current state of AI is clearly not as intelligent as the utmost majority of humans, yet several large players are happy to use it for important, often essential tasks. It seems the short-term gains (cost-saving) are prioritised over the long-term consequences (worse results due to less diversity and quality). I know, companies have been acting like that for ages, and they never seem to learn. Oh well.
A hearty welcome to new subscribers and followers! Many thanks for reading and stay tuned as I go deeper into consciousness (the thing AI is lacking) and other stuff.
While quite a lot, 570 GB is only a small part of the total amount of ‘data’ on the internet, which—according to Google CEO Eric Schmidt—is about 5 billion GB;
Thus, 570 GB accounts for 1/100,000th of all internet data;
Obviously, without a huge research effort, I can’t prove it;
Especially if it was English language only or predominantly;
Which theoretically—if AIs were really unbiased—would be a good thing. Unfortunately, AIs are just as biased as many human HR managers when screening job applicants;
Most probably because it’s considered too costly and because it might slow down the development of the next generation of AIs (competitive pressure), meaning they will—and have—become better at hiding their biases rather than fixing them;
See my inttroduction note before each post: I expressly forbid AIs to scrape my work (unfortunately that doesn’t seem to stop them);
As evidenced in the current actions of the American Department of Justice and the EU against Google and Apple, they do sometimes act, but quite late in the game (correction: the EU AI Act is an example of the opposite);
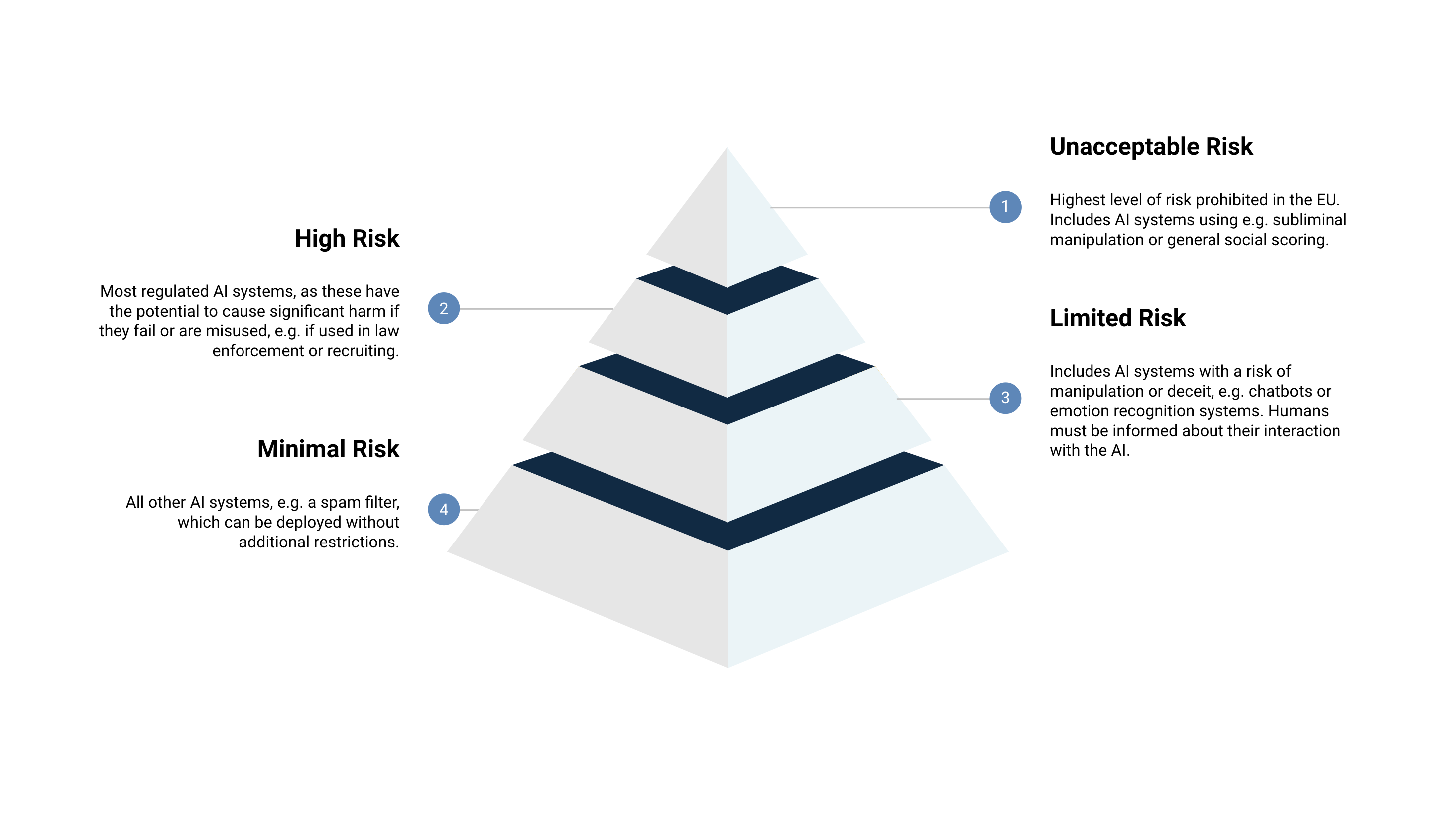
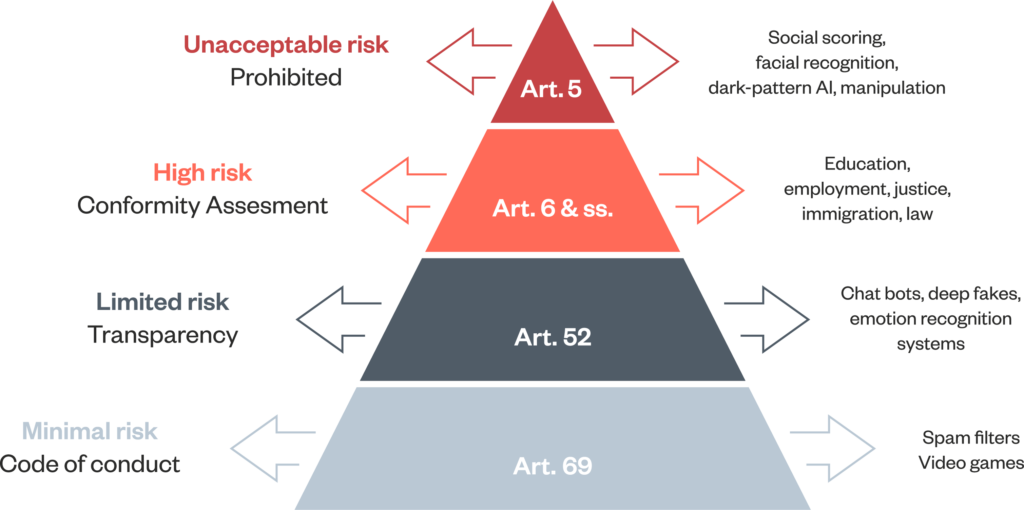
Unfortunately, it applies to ‘high-risk’ AI systems, and—see diagram—chatbots and deep fakes are considered ‘limited risk’;